Difference between revisions of "Food Computation"
Revathycv24 (Talk | contribs) (→(a) Mapping UFDA Ingredients to Recommend/Not Recommend for diabetes) |
Revathycv24 (Talk | contribs) (→Other Modules) |
||
| Line 62: | Line 62: | ||
===== Other Modules ===== | ===== Other Modules ===== | ||
Several other modules are underwork. This involves, integrating smoking point of fats and oils, incorporating glycemic index from University of Sydney Glycemic Index Database, Nutrition Retention of Ingredients and also integrating with ingredient substitution knowledge graph given in the next project. | Several other modules are underwork. This involves, integrating smoking point of fats and oils, incorporating glycemic index from University of Sydney Glycemic Index Database, Nutrition Retention of Ingredients and also integrating with ingredient substitution knowledge graph given in the next project. | ||
| − | |||
| − | |||
| − | |||
===3.Ingredient Substitution: Identifying suitable ingredients for health condition and food preferences === | ===3.Ingredient Substitution: Identifying suitable ingredients for health condition and food preferences === | ||
Revision as of 22:51, 18 November 2024
Contents
[hide]- 1 Motivation and Background
- 2 Projects
- 2.1 1.Explainable Recommendation: A neuro-symbolic food recommendation system with deep learning models and knowledge graphs
- 2.2 2. Multicontextual and Multimodal Food Knowledge Graphs
- 2.3 3.Ingredient Substitution: Identifying suitable ingredients for health condition and food preferences
- 2.4 4. mDiabetes: A mHealth application to monitor and track carbohydrate intake
- 2.5 5. Representation Learning: Cross-modal representation learning to retrieve cooking procedure from food images
- 3 Team Members
- 4 Press Coverage
- 5 Publications
Motivation and Background
Over the recent few years, people have become more aware of their food choices due to its impact on their health and chronic diseases. Consequently, the usage of dietary assessment systems has increased, most of which predict calorie information from food images. Various such dietary assessment systems have shown promising results in nudging users toward healthy eating habits. This led to a wide range of research in the area of food computation. Currently, at AIISC, the following projects are being carried out in the realm of food computation.
Projects
1.Explainable Recommendation: A neuro-symbolic food recommendation system with deep learning models and knowledge graphs
In this work, we propose a neurosymbolic food recommendation system that answers the question Can I have this food or not? Why?. Currently, the system focuses on chronic conditions such as diabetes The input can be in the form of text or images. Given a food image, the system will retrieve cooking instructions and extract cooking actions [2]. The ingredients and cooking actions will be analyzed with knowledge graphs and inferences will be drawn with respect to individual’s health condition and food preferences. Further, the system can suggest alternative ingredients and cooking actions. The system leverages generalization and pattern mining ability of deep learning models and reasoning ability of knowledge graphs to explain the recommendations or decisions made by the model. The notable features of the proposed approach are:
- Multi-contextual grounding: The ingredients and cooking actions are grounded with knowledge in several context. For example, potato is a healthy carbohydrate in the context of diabetes categories. In the context of glycemic index, it has high glycemic index. Further, we also capture nutrition, nutrition retention and visual representation of entities
- Alignment: The recommendation reasoning is aligned with dietary guidelines for diabetes from medical source
- Attribution: Each reasoning provided by the model can be attributed with the medical sources or published papers
- Explainability: The model employs several kinds of reasoning such as counterfactual reasoning, chain of evidence reasoning, path-based reasoning, procedural reasoning and analogical reasoning to explain the results
- Instructability: The model can take inputs from medical experts to adjust the process of meal analysis
We aim to build a custom, compact, neurosymbolic model to incorporate the above-mentioned abilities. While general-purpose generative models are trained on extensive data from the internet, including medical guidelines, extracting disease-specific dietary information from vast embedding spaces remains a significant challenge. Effective meal analysis requires a comprehensive understanding of various contexts, including medical guidelines, nutritional content, types of ingredients, the impact of cooking methods, and the user’s health condition and food preferences. These systems should be able to reason over the food by attributing their explanations to medical guidelines. Such systems should be custom trained for specific use cases. A neurosymbolic approach can harness rich knowledge sources, facilitating accountable and explainable reasoning.
Proposal Defense slides of Revathy Venkataramanan who is the project coordinator
2. Multicontextual and Multimodal Food Knowledge Graphs
To support the neurosymbolic recommender outlined in Project 1, various knowledge sources are combined to create a comprehensive, multicontextual, and multimodal food knowledge graph. The construction of the knowledge graph consists of the following modules:
(a) Mapping UFDA Ingredients to Recommend/Not Recommend for diabetes
This module focuses on gathering and mapping ingredient data from the United States Food and Drug Administration (USFDA) database and aligning it with dietary guidelines for diabetes from the Mayo Clinic and the National Institute of Diabetes and Digestive and Kidney Diseases (NIDDK). The resulting mappings assist in designing diets for diabetes patients based on expert recommendations. Below are some example mappings:
Potato → Categorized as Vegetables (USFDA) → Labeled as Healthy Carbohydrate (MayoClinic) → Recommend for Diabetes (MayoClinic) Pickled Sausage → Categorized as Sausages (USFDA) → Identified with Saturated Fat, Animal Protein (MayoClinic) → Avoid (MayoClinic) The mapping process uses a set of rules and keywords provided by MayoClinic to ensure accurate categorization. For instance, MayoClinic’s guidelines specify keywords and examples for both "recommend" and "avoid" categories. Nutritional profiles are also analyzed to classify ingredients effectively. Ingredients high in polyunsaturated and monounsaturated fats, such as those found in Omega-3 fatty acids, are marked as "good fats" and recommended for diabetes, while those containing saturated fat are marked as "avoid."
- Example
Salmon → Categorized as Finfish and Shellfish Products (USFDA) → Classified as Good Fats (MayoClinic) → Recommend (MayoClinic). More information can be found in the slides given below. Each ingredient can be associated with multiple diabetes categories. In the slides below, each Salmon is associated with Medium Fat, High Cholesterol, Heart Healthy Items, Low Sodium and Animal Protein. Each category is marked with the suggestive decisions from MayoClinic or NIDDK as Recommended, Avoid or Caution (have it with caution). For each ingredient and its paths, following information is present
- Path Based Reasoning: For each path, say, Salmon --> Medium Fat or Salmon --> Heart Healthy Fish, the reason behind this association is stored as shown in the slides.
- Explanation: For each ingredient, the explanation behind the classification is also stored. For example, Salmon is a keyword given by MayoClinic for Heart Healthy Fish. The nutrition of Salmon shows high cholesterol or medium fat as per source1, source2 and etc.
- Attribution/Provenance: For each ingredient, the source of information is also stored with them.
Diabetes Specific Diet Knowledge Graph
Other Modules
Several other modules are underwork. This involves, integrating smoking point of fats and oils, incorporating glycemic index from University of Sydney Glycemic Index Database, Nutrition Retention of Ingredients and also integrating with ingredient substitution knowledge graph given in the next project.
3.Ingredient Substitution: Identifying suitable ingredients for health condition and food preferences
Food is a fundamental part of life, and personalizing dietary choices is crucial due to the varying health conditions and food preferences of individuals. A significant aspect of this personalization involves adapting recipes to specific user needs, primarily achieved through ingredient substitution. However, the challenge arises as one ingredient may have multiple substitutes depending on the context, and existing works have not adequately captured this variability. We introduce a Multimodal Ingredient Substitution Knowledge Graph (MISKG) that captures a comprehensive and contextual understanding of 16,077 ingredients and 80,110 substitution pairs. The KG integrates semantic, nutritional, and flavor data, allowing both text and image-based querying for ingredient substitutions. Utilizing various sources such as ConceptNet, Wikidata, Edamam, and FlavorDB, this dataset supports personalized recipe adjustments based on dietary constraints, health labels, and sensory preferences. This work addresses gaps in existing datasets by including visual representations, nutrient information, contextual ingredient relationships, providing a valuable resource for culinary research and digital gastronomy.
Dataset
The dataset can be downloaded from
4. mDiabetes: A mHealth application to monitor and track carbohydrate intake
In this work, we developed a mobile health application to track carbohydrate intake of type-1 diabetes patients. The user will enter the food item name and their quantity in their convenient units. The app will query the nutrition database, perform necessary computation to convert the user entered volume to estimate the carbohydrates.
Resources
The app is under development to include food image-based carbohydrate estimation which requires food image based volume estimation.
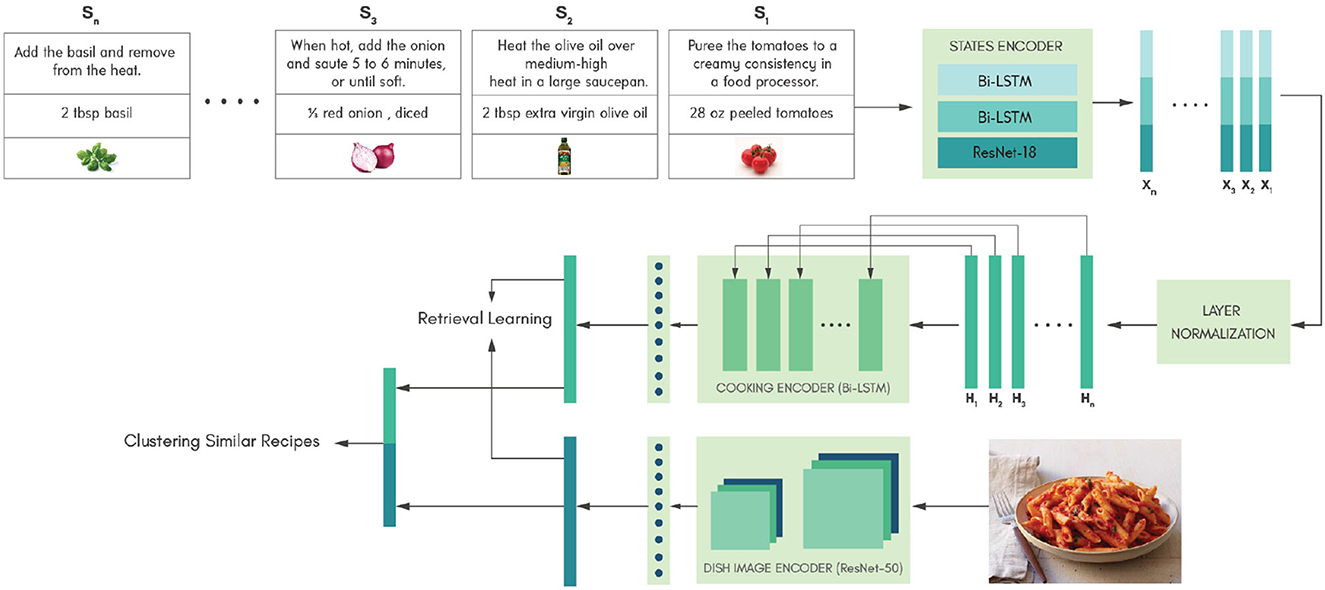
5. Representation Learning: Cross-modal representation learning to retrieve cooking procedure from food images
To support the explainable recommendation system (Project-1) in retrieving cooking instructructions from food images, we proposed a cross modal retrieval system described in Figure 4. In this work, we leverage knowledge infused clustering approaches to cluster similar recipes in the latent space [1]. Clustering similar recipes enables retrieval of more accurate cooking procedures for a given food image. Currently this network architecture is being enhanced and tested using transformer architectures.
Team Members
Coordinated by - Revathy Venkatramanan
Advised By - Amit Sheth
AIISC Collaborators:
- Kaushik Roy
- Yuxin Zi
- Vedant Khandelwal
- Renjith Prasad
- Hynwood Kim
- Jinendra Malekar
External Collaborators
Students/Interns
- Kanak Raj (BIT Mesra)
- Ishan Rai (Amazon)
- Jayati Srivastava (Google)
- Dhruv Makwana (Ignitarium)
- Deeptansh (IIIT Hyderabad)
- Akshit (IIIT Hyderabad)
Professors/Leads
- Dr.Lisa Knight (Prisma Health - Endocrinologist)
- Dr. James Herbert (USC - Epidemiologist and Nutritionist)
- Dr. Ponnurangam Kumaraguru (Professor - IIIT Hyderabad)
- Victor Penev (Edamam - Industry collaborator)
Press Coverage
- Edamam Provides Data for the Creation of an AI Model for Personalized Meal Recommendations. Read More:https://whnt.com/business/press-releases/ein-presswire/744188562/edamam-provides-data-for-the-creation-of-an-ai-model-for-personalized-meal-recommendations/
Publications
- Venkataramanan, Revathy, Swati Padhee, Saini Rohan Rao, Ronak Kaoshik, Anirudh Sundara Rajan, and Amit Sheth. "Ki-Cook: Clustering Multimodal Cooking Representations through Knowledge-infused Learning." Frontiers in Big Data 6: 1200840.
- Venkataramanan, Revathy, Kaushik Roy, Kanak Raj, Renjith Prasad, Yuxin Zi, Vignesh Narayanan, and Amit Sheth. "Cook-Gen: Robust Generative Modeling of Cooking Actions from Recipes." arXiv preprint arXiv:2306.01805 (2023).
- Sheth, Amit, Manas Gaur, Kaushik Roy, Revathy Venkataraman, and Vedant Khandelwal. "Process knowledge-infused ai: Toward user-level explainability, interpretability, and safety." IEEE Internet Computing 26, no. 5 (2022): 76-84.