Difference between revisions of "Twarql"
(→Introduction) |
(→Brand Tracking Scenario: IPad) |
||
| Line 24: | Line 24: | ||
=== Brand Tracking Scenario: IPad === | === Brand Tracking Scenario: IPad === | ||
For the Triplify Challenge 2010 we have collected tweets mentioning iPad from June 3rd until Jun 8th to demonstrate our system in a brand tracking scenario. | For the Triplify Challenge 2010 we have collected tweets mentioning iPad from June 3rd until Jun 8th to demonstrate our system in a brand tracking scenario. | ||
| − | |||
<!-- | <!-- | ||
The dataset is available via a SPARQL Endpoint http://.... (Powered by Openlink Virtuoso). | The dataset is available via a SPARQL Endpoint http://.... (Powered by Openlink Virtuoso). | ||
| Line 34: | Line 33: | ||
http://knoesis1.wright.edu/library/tools/twarql/TwarqlIPadTweets.nt.gz | http://knoesis1.wright.edu/library/tools/twarql/TwarqlIPadTweets.nt.gz | ||
| − | Total Number of tweets : 511,147 | + | * Total Number of tweets : 511,147 |
| − | Sentiment: 53,237 positive; 6,739 negative; 451,171 neutral. | + | * Sentiment: 53,237 positive; 6,739 negative; 451,171 neutral. |
<!-- | <!-- | ||
| − | Location: XXX tweets with geolocation; YYY without geolocation. Most common location: ZZZ. | + | * Location: XXX tweets with geolocation; YYY without geolocation. Most common location: ZZZ. |
| − | Competitors: XXX tweets with competitors; Most cooccuring competitor: ZZZ. | + | * Competitors: XXX tweets with competitors; Most cooccuring competitor: ZZZ. |
--> | --> | ||
Revision as of 09:24, 23 June 2010
Twarql: Twitter Feeds through SPARQL
{kind=link}
-->
Contents
Introduction
Our approach encompasses the following steps:
- extract content (entity mentions, hashtags and URLs) from microposts;
- encode content in a structured format (RDF) using shared vocabularies (FOAF, SIOC, MOAT, etc.);
- enable structured querying of microposts (SPARQL);
- enable subscription to a stream of microposts that match a given query (Concept Feeds);
- enable scalable real-time delivery of streaming data (SparqlPuSH).
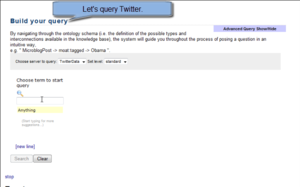
Demonstration We have two demonstration videos. The first video demonstrates the user perspective, interacting with the system to formulate a query and obtain microblog posts that match that query. The second video focuses on the server side and demonstrates the modules of our architecture at work, distributing the microposts via pubsubhubbub.
Brand Tracking Scenario: IPad
For the Triplify Challenge 2010 we have collected tweets mentioning iPad from June 3rd until Jun 8th to demonstrate our system in a brand tracking scenario.
You can download a sample of the triples generated at: http://knoesis1.wright.edu/library/tools/twarql/TwarqlIPadTweets.nt.gz
- Total Number of tweets : 511,147
- Sentiment: 53,237 positive; 6,739 negative; 451,171 neutral.
Architecture
See the workflow between the components of the architecture:
Tweet Annotation
- extract content from microposts;
- entity mentions (e.g. from DBpedia)
- hashtags
- URLs
- user mentions
- encode content in a structured format (RDF) using shared vocabularies (FOAF, SIOC, MOAT, etc.);
We offer Twarql Annotation both as REST and Java APIs. You can download our source code and easily extend the annotation pipeline with your own extractors.
Concept Feeds
- enable structured querying of microposts (SPARQL);
- enable subscription to a stream of microposts that match a given query;
SPARQLPuSH
- More about the SPARQL Push implementation: Introducing sparqlPuSH, open source implementation
Twarql API
REST Endpoints
Summary:
- URL scheme: http://<base-url>/<operation>/?<parameter>=<value>&...&output=<output format>
- Base URL: http://knoesis1.wright.edu/twarql
- Operations: search, register, stream, query
- Output formats: twitter-json, sparql-json, entities
Parameters:
- http://knoesis1.wright.edu/twarql/search?keyword=k1,...,kn&output=<output type>
- input: keywords, output type (tweets, entities, sparql)
- output: tweets, entities, triples
- http://knoesis1.wright.edu/twarql/search?keyword=k1,...,kn&output=<output type>
- D2R
- http://knoesis1.wright.edu/twarql/register?query=<sparql query>&id=<concept feed id>
- #id
- http://knoesis1.wright.edu/twarql/stream?keyword=k1,...,kn&id=<registered concept feed id>&output=<output type>
Output Formats
We also provide output according to the format presented on the twitter-api-announce message.
{
"text" : "hey @raffi tell @noradio to check out http://dev.twitter.com #hot",
...
"entities" : {
"user_mentions" : [
{
"id" : 8285392,
"screen_name" : "raffi",
"indices" : [4, 9]
},
{
"id" : 3191321,
"screen_name" : "noradio",
"indices" : [16, 23]
}
],
"urls" : [
{ "url" : "http://dev.twitter.com",
"indices" : [38, 64]
},
],
"hashtags" : [
{ "text" : "#hot",
"indices" : [66, 69]
"url" : "http://search.twitter.com/search?q=%23hot"
}
]
}
...
}
Error/Warning Messages
ERROR
- Unknown Stream: You are requesting a stream id that was not registered.
- Invalid Query: You are trying to register an invalid SPARQL query.
- Unsupported Content-type: The requested content type is not supported.
WARNING
- No Results: There are no results for the query.
Supported Clients
- SPARQL Protocol-compliant Clients
- Cuebee is a SPARQL query formulation and results exploration engine. We provide a TweetExplorer that can be directly plugged into Cuebee.
- RSS/Atom clients
- View SparqlPuSH
People
You may contact us if you have any questions about the implementation or API. We have listed our major contributions below our names so that you know to whom you should direct your question.
- Pablo Mendes (@pablomendes)
- Architecture, SPARQL client (Cuebee), Social Sensor (Extraction, Annotation), API, Documentation
- Pavan Kapanipathi (@pavankaps)
- Application Server, Semantic Publisher, Streaming SPARQL, API Content Negotiation
- Alex Passant (@terraces)
- SparqlPuSH, Annotation Vocabularies