Similarity rank
Similarity rank is designed to rank similar items in a graph based on Wikipedia. First the wikipedia graph is transformed into its matrix transformation, and cosine similarity is used to calculate the value.
Wikipedia Graph
A DirectedSparseMultigraph is used to create the graph, from the jung package. There are four types of edges: RegularEdge, SeeAlsoEdge, RegularBackEdge, SeeAlsoBackEdge. This is transformed into a matrix. Where each row and column represent a vertix in the graph and the value of the cell is the wieght of the edge. Since a matrix cannot have more than one edge, a single weight must be chosen. First it selects the highest weight and uses that, but if it is doubly-linked, then a different(higher) value is used, chosen from the constants DoubleRegularWeight and DoubleSeeAlsoWeight. The matrix is sparse and uses a SortedArrayMap for the rows.
The ranking
Cosine similarity is used to calculate the ranking:
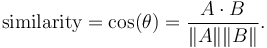
It takes advantege of the sorted rows to calculate the inserection of two ros.