Doozer
Doozer is an on-demand domain hierarchy creation application that is available as a Web Service[1]. It uses the power of user-generated content on Wikipedia by harnessing the rich category hierarchy, link graph and concept descriptors. For an in-depth discussion of the technical details, please refer to C.Thomas et al., 2008 <ref>C. J. Thomas, P. Mehra, R. Brooks, and A. P. Sheth, Growing Fields of Interest - Using an Expand and Reduce Strategy for Domain Model Extraction,” Web Intelligence and Intelligent Agent Technology, IEEE/WIC/ACM International Conference on, vol. 1, pp. 496-502, 2008.</ref>. Doozer is predecessor to Doozer++, which incorporates information extraction techniques to automatically extract domain models that contain named relationships between concepts in addition to a concept hierarchy.
Introduction
It is widely agreed on that having a formal representation of domain knowledge can leverage classification, knowledge retrieval and reasoning about domain concepts. Many envisioned applications of AI and the Semantic Web assume vast knowledge repositories of this sort, claiming that upon their availability machines will be able to plan and solve problems for us in ways previously unimaginable <ref name="BLSemWeb">Tim Berners-Lee,James Hendler and Ora Lassila, The Semantic Web, Scientific American Magazine , May 17, 2001</ref>.
There are some flaws in this. The massive repositories of formalized knowledge are either not available or do not interoperate well. A reason for this is that rigorous ontology design requires the designer to fully comply with the underlying logical model, e.g. description logics in the case of OWL-DL. It is very difficult to keep a single ontology logically consistent while maintaining high expressiveness and high connectivity of the domain model, let alone several ontologies designed by different groups.
Another problem is that Ontologies, almost by definition, are static, monolithic blocks of knowledge that are not supposed to change frequently. The field of ontology was concerned with the essence and categorization of things, not with the things themselves. The more we venture in the abstract, the less change we will encounter. The notion of what the concept of furniture is, for example, has not changed significantly over the past centuries despite the fact that most individual items of furniture look quite different than they did even ten years ago. Our conceptualization of the world and of domains stays relatively stable while the actual things change rapidly. In the year 2005, about 1,660,000 patent applications were filed worldwide , 3-4Gb of professionally published content are produced daily <ref>R. Ramakrishnan and A. Tomkins, Toward a peopleweb, IEEE Computer, vol. 40, no. 8, pp. 63-72, 2007.</ref>. Keeping up with what is new has become an impossible task. Still, more than ever before, we need to keep up with the news that are of interest and importance to us and update our worldview accordingly. One inspiration for this work was given by N.N.Taleb's Bestseller The Black Swan <ref name = "swan">N.N. Taleb, The Black Swan, Second Edition, Penguin, 2010</ref>, a book about the impossibility to predict the future, but the necessity of being prepared for it. The best way to achieve this is to have the best, latest and most appropriate information available at the right time. "It's impossible to predict who will change the world, because major changes are Black Swans, the result of accidents and luck. But we do know who society's winners will be: those who are prepared to face Black Swans, to be exposed to them, to recognize them when they show up and to rigorously exploit them."<ref name = "swan"/>
We want to be the first to know about change, ideally, before it happens, at least shortly after. The Black Swan paradigm for information retrieval is thus \textbf{``What will you want to know tomorrow?} The news we want to see need to give us more information than we already have, not reiterate old facts. News delivery also needs to take changes in domains into account, ideally without the userÕs interference, because the user relies on being informed about new developments by the news delivery system itself. Classification based on corpus-learning or user input can only react to changes in the domain, never be ahead of it. Ways of being up-to date with the current information are e.g. following storylines by trying to capture the direction that previous news items were taking and updating a training corpus accordingly or by constantly updating a domain model. Our work is aiming at the latter, assuming that social knowledge aggregation sites such as Wikipedia contain descriptions of new concepts very quickly.
Doozer is part of a pipeline for news classification that aims at identifying content that could be of immediate interest for different domains. A domain is described by an automatically generated domain model. The underlying knowledge repository from which the model is extracted is Wikipedia, likely the fastest growing and most up-to-date encyclopedia available. Its category structure resembles the class hierarchy of a formal ontology to some extent, even though many subcategory relationships in Wikipedia are associative rather than being strict is_a relationships; neither are all categorizations of articles strict type relationships, nor are all articles representing instances. For this reason we refrain from calling our resulting domain model an ontology. This work does not aim at solving the problem of creating formal ontologies. Whereas ontologies that are used for reasoning, database integration, etc. need to be logically consistent, well restricted and highly connected to be of any use at all, domain models for information retrieval can be more loosely connected and even allow for logical inconsistencies.
Model Creation
Doozer is a available in a simplified version as a Web Service that only requires the input of a domain description in the form of a keywords query. The query follows the Lucene query syntax and is by default disjunctive. The web interface is available here.
An introductory video can be found here.
Example Models
In this section we show some models that were automatically extracted using Doozer. These range from models that were inspired by Information Retrieval and filtering tasks to models that described scientific domains. The IR-inspired models revolved around filtering of ongoing events, such as the Arab Spring in early 2011, specifically the protests in Egypt. The scientific models were built for the domains of Neoplasms and of Cognitive Performance.
Oncology

Cognitive Science

Models for Information Retrieval Tasks
The following Images show models that were created on-the-fly for Information Retrieval purposes. The following example models were created using the Web Service interface with the following keyword queries:
| Domain | Query |
|---|---|
| Beatles | Beatles "John Lennon" "Paul McCartney" songs |
| Harry Potter | "Harry Potter" Gryffindor Slytherin |
| Financial crisis - TARP | tarp "financial crisis" "toxic assets" |
Example 1: Beatles Songs and related concepts

Example 2: Harry Potter

Example 3: 2008 Financial Crisis - TARP

Approach
In this section we describe domain hierarchy creation, the first step toward domain model creation. There are several methods involved in creating a comprehensive domain hierarchy from a simple query or a set of keywords. The overall process follows an Expand and Reduce paradigm that allows us to first explore and exploit the concept space before reducing the concepts that were initially deemed interesting to those that are most important and most significant to the domain of interest. We decided to look at a domain of interest from three different levels. \item The Focus, which is at the center of interest. \item The Domain, which encompasses concepts that are immediately related to concepts in the Focus. \item The World View, which prioritizes some concepts and links over others, based on a category that marks the point of view.
The Focus of the domain is described in the form of a keyword query. The Domain is provided in the form of one or more categories that the user wants the model restricted to. The World View is given in the form of a single category that determines the way concepts are categorized. Table shows combinations of Focus queries, Domain and WorldView categories. Since the Focus is described by a query, we show a query syntax. In the Web 2.0 examples, it can easily be seen that the first example aims at creating a model that looks at Web 2.0 from a sociological point of view, whereas the second example gears the creation toward a technical direction.
| Focus | Domain | WorldView | |
|---|---|---|---|
| 1 | Neoplasms | Oncology | Medicine |
| 2 | Cognitive Psychology | Cognitive Science | Science |
| 3a | "Web 2.0" AND Netizen | Social Networking | Society |
| 3b | "Web 2.0" AND Ajax | Internet | Information Science |
Whereas the Focus is based on an individual choice of keywords, Domain and WorldView are dependent on the community-created category hieararchy on Wikipedia and thus emphasize the shared aspect of model creation. The WorldView is generated by topologically sorting the categories of Wikipedia with respect to the chosen category. This sorting is performed by executing a breadth-first search through the category graph starting from the upper category. Only those category links are kept that provide the shortest path from the chosen root category. The assumption behind this uninformed method is that the community that created the topic hierarchy asserted subcategories that are most important to a category closer than subcategories that are only marginally related.
For the steps involved in Expand and Reduce, the ontology creation takes advantage of several well-proven tools for knowledge aggregation:
\item Expansion
- Full-text Search # Graph-based expansion # Category-growth # Reduction
- Category-based reduction/intersection # Conditional pruning # Depth reduction
In the following, we will describe these methods in depth.
Expansion
This subsection describes the expansion steps taken to get from a simple domain description, such as a glossary or simply a query to a possibly exhaustive list of terms relevant to the domain (Figure ). In the expansions steps we maximize recall to allow as many concepts as possible to be taken into account while maintaining a sensible focus on the domain of interest.
[file:Doozer-Expansion] Full Text Search - Exploring the knowledge space Any indexed Wikipedia article that matches a query with a score greater than a given threshold and/or smaller than a given maximum rank (depending on user preferences) will be returned, regardless of whether it ultimately matches the desired focus domain or not. However, a carefully stated query will help maintain the focus even in this early stage. The set of concepts Csearch returned from this step is described in Formula . We chose to give the user the option of scored and ranked search because the raw score given by the Lucene indexer is not always intuitive, especially when searching for more elaborate Boolean expressions.
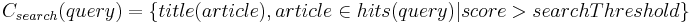
and/or
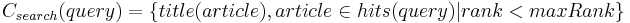
'Graph-Based Expansion - Exploiting the knowledge space The graph-based expansion returns articles that are semantically closely related to the initial search results, even if the articles do not match the focus query. The graph based expansion follows a semantic similarity method, because similarity is computed using links between Wikipedia pages. The importance or similarity of adjacent articles is measured using a weighted common neighbors metric<ref name="SemSim">[1] D. Lizorkin, P. Velikhov, M. Grinev, and D. Turdakov, Accuracy estimate and optimization techniques for SimRank computation, PVLDB, vol. 1, no. 1, pp. 422-433, 2008.</ref>. The semantic similarity between nodes a and b is given in equation , which is defined as the sum of weights of their shared neighbors (articles that are linked to or link to the current article), normalized by the node degrees. Let M be the adjacency matrix of Wikipedia, N(a) stands for the neighborhood and w(N(a)) stands for the weight of as neighboring nodes, and includes all the articles that link to or are linked to a. This weight depends on the kind of link between a and each of its neighbors.
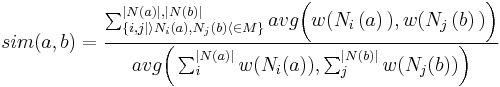
The link weights w to the neighboring nodes can vary for different document links considered. Figure shows the different types of links in Wikipedia as described in <ref>[1] D. Turdakov and P. Velikhov, Semantic Relatedness Metric for Wikipedia Concepts Based on Link Analysis and its Application to Word Sense Disambiguation, in SYRCoDIS, 2008</ref>. The weights for each of these types of links were empirically determined. We emphasized on the see-also links, because editors add these links usually to refer to highly relevant concepts. Double links also indicate that two concepts are mutually important for each other. By the same rationale we gave single links in one or the other direction low weights. Many articles, for example, have a link to years or countries, but only if the linked articles also contain a link back can we assume that the original article is actually important for the year, the country, etc. The set C_{sim} of nodes with highest similarity to the initial nodes are then chosen to be in the domain model (see Equation )
[file:WikipediaLinksOrig2]
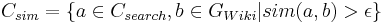
The final set of terms gained during the expansion steps is the union of the initial search results and their graph-based expansions (Equation ).
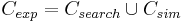
Building a category hierarchy Building a category hierarchy is an essential step for further pruning. Categories are connected with respect to the World View taken, rather than using the entire graph structure of Wikipedia.
Equations and describe the iterative growth of the category hierarchy. In Equation , the immediate types/categories T1 are selected that contain the concepts from Cexp; Equation describes finding the super-categories to the categories in Ti within the world view TWorldview and adding them to the set of categories in the hierarchy.
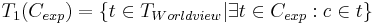
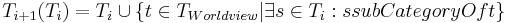
Where Ti is the set of categories (i.e. types) at iteration i, t denotes a single category and c 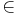 t denotes a concept categorized in category t.
t denotes a concept categorized in category t.
Reduction
Whereas the expansion steps are used to gather knowledge in a recall-oriented way, the reduction steps increase precision and reduce the set of terms to the focus domain.
Probability-based reduction: Conditional Pruning For each term in the list of extracted terms, we compute a relevance probability with respect to the broader domain of interest. Equation shows this conditional probability computation. A probability of 1.0, for example would indicate that every time the term appears, it is within the domain of interest. Equation shows the inverse: how commonly used is the term in the domain? Knowing both measures is not only important for this pruning step, but also for the subsequent use of the created domain model in probabilistic document classification tasks. If the importance of a term is less than one of the predefined thresholds \epsilon 1, \epsilon 2, it is discarded from the set of domain terms.
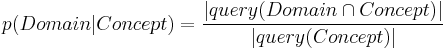
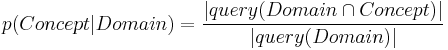
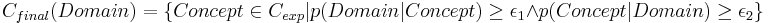
Category-based reduction After probabilistic pruning, some categories (and their subcategories) will be empty. These can by default be deleted. Furthermore, all categories that do not belong to the chosen broader focus domain, including all terms that are not categorized within the broader focus, are deleted immediately. If a term is categorized in more than one category, it is kept in the categories that are part of the broader focus domain, otherwise it is deleted. If a term is the only term in a category, it is moved up to the next higher category in the hierarchy.
Depth Reduction In many cases, after the category-based reduction, deep linear branches of categories remain as artifacts of the category building and deletion tasks. We assume that unpopulated and unbranched category hierarchies can be collapsed without loss of relevant knowledge. This step reduces the depth and increases the fan-out of the domain model. Together with the previous step it reduces the number of resulting categories to make the model easier manageable.
After expansion and reduction, the intermediate model consists of a category hierarchy and concept nodes that are annotated with the conditional probabilities of their importance in the domain and for the domain (p(Article|Domain) and p(Domain|Article)). The concept nodes are named with the corresponding Wikipedia article names. In the following, the nodes are enriched with alternative descriptors.
Synonym Acquisition
Since the extraction of domain models is concept-based, rather than term-based, it is necessary to find alternative denotations or labels for the concepts in the hierarchy. The Wikipedia article names are unambiguous identifiers and as such not necessarily of the form we are used to talking about the concept described by the article. The Wikipedia article for the capital of the United States, for example has the Wikipedia name ``Washington,_ D.C. as a unique identifier. We expect to find different identifiers in text, though, such as ``Washington or just ``D.C.. A domain model that is used for information extraction and text classification needs to contain these identifiers and synonyms for the concept of the article. One good source of synonyms is WordNet<ref>C. Fellbaum, WordNet: An Electronic Lexical Database. The MIT Press, 1998.</ref>, but it requires to first unambiguously identify a match between a Wikipedia article name and a WordNet Synset, which adds another level of uncertainty. Furthermore, WordNet, despite a great overlap, has a different scope and is more static than Wikipedia. A major reason to extract knowledge from Wikipedia was, however, to have an almost instantaneous update of world-knowledge as new concepts become known or as new events unfold. Anchor texts have proven to be a good indicator for alternative concept labels <ref>S. Brin and L. Page, The anatomy of a large-scale hypertextual web search engine, Proc. 7th Int’l World Wide Web Conf. (WWW7), pp. 107-117, 1998.</ref>. More than on the web, where the concept described by a page is not entirely certain, on Wikipedia, there is a direct concept associated with the link. Hence we decided to stay within the Wikipedia corpus and analyze the anchor texts that link to the respective articles. The probability that a term is a synonym of an Article name and hence an identifier of the concept described by the article is given by Equation , the conditional probability that a term links to an unambiguous article:
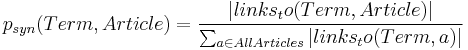
In the domain hierarchy, these synonyms are represented as labels as well as individual values of annotation properties that contain both the term and psyn, so the synonyms can be used in classification.
Serialization
The resulting domain models are serialized either as OWL files or as RDF files using SKOS relationships. An OWL serialization reflects a view of the Wikipedia category graph as a class hierarchy whereas SKOS describes category membership and subcategory relationships that do not follow proper inheritance rules. The serialization based on Semantic Web standards greatly facilitates accessibility, manual modification and visualization. When serializing as an OWL file we turn subcategory relationships into subclass relationships, and thus need to be aware of the fact that this may not meet the formal standards of OWL; the Wikipedia category hierarchy is often associative rather than expressing formal is_a relationships. However, knowing about the limitations of the generated models, OWL as the W3-recommended ontology language is a good way to make the models widely accessible.
Evaluation
Guarino <ref>Y. Sure, Gomez, W. Daelemans, M.-L. Reinberger, N. Guarino, and N. F. Noy, Why Evaluate Ontology Technologies? Because It Works!,IEEE Intelligent Systems, vol. 19, no. 4, pp. 74-81, 2004.</ref> suggests to compare a new ontology to a canonized domain conceptualization and then measure precision and recall by determining how well the ontology covers the conceptualization. Conceptually, this is a good method to determine ontology quality, but it causes practical problems, because when we use such a conceptualization as a gold standard to test the performance of the system, the problem of mapping between concept descriptions in both has to be resolved. Moreover, in many domains in which automatic extraction of ontologies or domain models would be desirable, no ready-made conceptualizations exist that could be used as a gold standard.
We decided to evaluate the extracted hierarchies qualitatively and quantitatively. In the qualitative analysis we manually compare the outcome of a focus query against the outcome of the same (or similar, but optimized) query to a comparable service. In the quantitative analyses, we compare different generated hierarchies against gold standard taxonomies and glossaries. For these analyses we chose to create models from the financial domain and the biomedical domain, where we can compare to a trusted taxonomy in the form of the MeSH hierarchy.
In all these evaluation methodologies we only evaluate the presence of concepts/entities in the hierarchy, not their placement in the hierarchy. The reason is that the extracted hierarchy is copied from the Wikipedia category hierarchy and thus only as good as Wikipedia itself.
Comparable services
To measure the quality of the results produced by Doozer, we created domain taxonomies and compared them with tools specialized in mining Wikipedia and human-composed glossaries. These comparisons are now described.
Sets by Google Labs: The (now discontinued) service allowed the user to input between one and five example concepts. When comparing with domains created by our method using really short seed queries, such as "mortgage" or "database" or "federal reserve", we found Google Sets worked better if that seed was repeated as an example five times rather than just once with four null inputs. Sets was also the only service we used in our comparisons that could not be restricted to return results that lie within the Wikipedia name space.
Grokker by Groxis, Inc.: This (now discontinued) service allowed the user to find and organize related concepts, and can be constrained to return only Wikipedia concepts. We invoked the service using our seed query, with the exception of introducing white space and explicit OR keywords where necessary.
PowerSet is a service to mine Wikipedia using either simple queries or natural language questions. Where Power Labs returned better results using a question rather than a seed query, as was the case for instance with "What about mortgage" versus "mortgage", we used the input that produced higher-quality results.
Finally, we also compared against results obtained using Wikimedia search, i.e. the default Wikipedia search option, which takes our unmodified seed queries. Since a full-text search is the first step in creating domain hierarchies, this comparison gives a good idea of the information gain we get using the graph expansion step.
Qualitative comparison of top-10 ranked results
Given a domain taxonomy, our analysis proceeds by comparing the different lists of terms generated for the same query by the above mentioned services, first against each other and then against a standard reference. Table shows the top ten results returned against the query "mortgage". Some services show rapid deterioration even in the first ten results. For instance, while finding gems such as "houses for sale" and "personal finance", Google Sets also finds irrelevant concepts such as "photos" and "overview". Likewise, Grokker brings up several loosely related terms such as "Tort law" and the very generic but relevant term "Bank" among its top ten hits. Powerset does well to find "2007 Subprime mortgage financial crisis," perhaps from a direct keyword hit, and Wikipedia Search likewise brings up several keyword hits. Doozer also brings up some loose hits such as "UK Mortgage Terminology", but does rather well to find "interest-only loan". Doozer and Grokker do well to find more than just keyword hits, while still keeping good precision.
| Google Sets | Grokker | Doozer | Powerset | Wikimedia | |
|---|---|---|---|---|---|
| 1st | mortgage | Tort law | Mortgage | Mortgage Loan | Mortgage loan |
| 2nd | overview | Lost, mislaid, and abandoned property | Mortgage | Mortgage broker | Mortgage loan |
| 3rd | contact brochures | Mortgage loan | Teachers' Building Society | Mortgage underwriting | Mortgage-backed security |
| 4th | photos | Law of Property Act 1925 (c.20... | Mortgage-backed Security | Subprime mortgage financial crisis | Mortgage discrimination |
| 5th | personal finance | Leasehold estate | Agency Securities | Mortgage discrimination | Mortgage discrimination |
| 6th | foreclosures | Non-possessory interest in land | Uk Mortgage Terminology} | Shared appreciation mortgage | Mortgage broker |
| 7th | houses for sale | Bank | Mortgage Note | Mortgage insurance | Mortgage bank |
| 8th | real estate training | Non-recourse debt | Adjustable Rate Mortgage | Biweekly Mortgage | Adjustable rate mortgage |
| 9th | people search | Lateral and subjacent support | Graduated Payment Mortgage Loan | Mortgage | Lenders mortgage insurance |
| 10th | mortgage lending tree | Mortgage | Interest-only Loan | Foreign currency mortgage | Ameriquest Mortgage |
Quantitative comparison of tools against a reference taxonomy
The ideal reference list should be agreed upon by domain experts and disambiguated with other domains. In what follows, we interpret terms with high relevancy as those which are put into the domain by agreement among domain experts and have negligible, if any, ambiguity with other domains. In absence of an ideal reference list, the reference lists used in this work are formed from domain glossaries of terms. To further measure the accuracy with which the tools discover relevant terms from the same training corpus, i.e., Wikipedia, we have also correlated the terms in the domain glossaries with the list of terms produced from a topic search of the Wikipedia corpus. In our analysis, we used a glossary of financial terms which has been pre-categorized into domains. In particular, we utilized the list of terms in the federal reserve and mortgage domains. The tools from Google, Grokker, Powerset, and Wikipedia as well as ours, were each queried with each of these two seeds to produce two domain lists per tool. Since the financial glossary regards all its terms as equally relevant, so did we drop any weights, probabilities and ranking computed by the tools; thus, all of the terms, appearing in each tool's list, are equally relevant within that list. In order to reduce the terms from the glossary down to only the ones found in a search for the respective seed topics in Wikipedia, we produced the reference list as the intersection of the respective glossary and Wikipedia search results. These reference lists then contain terms that the author of the glossary would consider relevant to the respective domains and that are also present in the corpus upon which the taxonomies are built. The values of the measure <ref>R. Y. K. Lau, Fuzzy Domain Ontology Discovery for Business Knowledge Management, IEEE Intelligent Informatics Bulletin, vol. 8, no. 1, pp. 29-41, 2007.</ref> were then computed with (equal weight for precision and recall) for the lists generated by the tools. The results are illustrated in Figure 33. We note that Doozer's results for are at least a factor of two improvement over those of the other tools. This difference in performance can be attributed to the amount of noise in the topic search results of Wikipedia. In order to quantify this further, we considered the fact that there might be some relevant terms which appear in the topic search results from Wikipedia but do not appear in the glossary. Thus, we compute the fraction of relevant terms found in a topic search of Wikipedia as
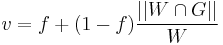
where W refers to the set of search results from Wikipedia, G is the set of terms in the glossary, and f is the fraction of terms from any snapshot of the complement of  in W that are deemed to be relevant to the domain. Using the "mortgage" domain as a test case, we formed the disjunction of the lists from the glossary and search results from Wikipedia. We then took a random snapshot of the terms in the disjunction and then found those terms that were present in the search results from Wikipedia and relevant to the mortgage domain; this gave us an estimated value for t. The stemmed terms from the snapshot are listed in Table .
in W that are deemed to be relevant to the domain. Using the "mortgage" domain as a test case, we formed the disjunction of the lists from the glossary and search results from Wikipedia. We then took a random snapshot of the terms in the disjunction and then found those terms that were present in the search results from Wikipedia and relevant to the mortgage domain; this gave us an estimated value for t. The stemmed terms from the snapshot are listed in Table .
| Glossary but not Wikipedia | Wikipedia but not Glossary | |
|---|---|---|
| 1 | first mortgag | metavant corpor |
| 2 | decre of foreclosur and sale | Centrepoint |
| 3 | Remedi | Ghetto |
| 4 | finder's fee | first bancorp |
| 5 | lien holder | mortgag interest relief at sourc |
| 6 | industri bank | clear titl |
| 7 | shared-appreciation mortgag | home mortgag interest deduct |
| 8 | call provis | crane v |
| 9 | Indentur | nomura secur co |
| 10 | pariti claus | person properti |
| 11 | open mortgag | Mew |
| 12 | interest-only strip | callabl bond |
| 13 | mandatori deliveri | alli dunbar |
| 14 | grow equiti mortgag | termin deposit |
| 15 | product risk | dodgeball: a true underdog stori |
| 16 | pledg loan | truth in lend act |
| 17 | fund from oper | Wala |
Using Equation , the percentage of the search results in Wikipedia that are relevant is estimated to be 32\These results provide evidence that the use of topic search results of Wikipedia will have high rates of both false positives and false negatives if they were used as the sole basis for taxonomies. As described above, the approach reported in this work increases the recall primarily by exploiting the link structure of Wikipedia to find additional topics that are similar to an initial set of topics. Furthermore, we use domain relevancy statistics (weights and conditional probabilities) to prune intermediate lists, thereby increasing the precision of Doozer's results, as evidenced by the results in Figure .

Comparison against MeSH

Comparing the generated list of domain terms to a Gold Standard such as MeSH allows us to get a quantitative evaluation of the extraction quality in a scientific field. However, this kind of comparison is biased towards the concepts in the gold standard. Terms in the extracted model that are relevant, but not in the gold standard will not count towards the model's precision and recall. Domain ontologies and glossaries usually contain terms for immediate domain concepts rather than terms that are highly indicative of a domain. The term "cancer", for example is very important for, but not highly indicative of the oncology field. The content of the created domain models are meant to be used in retrieval and classification tasks. For this reason, finding the phrase "MIT Center for Cancer Research" in an article is very indicative of the oncology domain, but not useful in a specific biomedical taxonomy such as MeSH. Nevertheless, in order to have a numerical evaluation of the ontology creation process, an automated Gold-Standard evaluation <ref>J. Brank, M. Grobelnik, and D. Mladenic, A survey of ontology evaluation techniques, in Proceedings of the Conference on Data Mining and Data Warehouses (SiKDD 2005), 2005, p. 166--170.</ref> is performed. We extracted all MeSH terms in the Neoplasms subtree to compare them against an automatically generated Neoplasms domain model. For the extraction, the algorithm was run with the following description:
\item Focus description: (Adenoma Carcinoma Vipoma Fibroma Glucagonoma Glioblastoma Leukemia Lymphoma Melanoma Myoma Neoplasm Papilloma) AND (medicine medical oncology cell disease) \item Domain categories: oncology, medicine, types of cancer \item World view: Biology
An abstract view of this domain model is shown in Figure 4. The visualization is done using the Jambalaya environment. Using the size of the boxes as indicators of the relative number of descendants, it is apparent that the "types of cancer" category gets the largest weight in the domain model. In fact, out of a total of 222 extracted instances, 135 belong to the category "types of cancer".
Just like Wikipedia, MeSH is constantly evolving, albeit the changes are performed by domain experts only. In order to show how useful an automatic extraction of a domain model can be to stay up-to-date without investing human effort, the extracted domain model is compared against the Neoplasm subtrees of the MeSH versions from the years 2004 and 2008. Alignment of Wikipedia and MeSH is not in the scope of this work, therefore we only evaluate string matches between the extracted domain model and the Neoplasms subtree. The terms in the generated domain model are matched against two subsets of both MeSH Neoplasms versions. (1) is the full set of terms, (2) is the subset of MeSH terms that can actually be found in the Wikipedia titles and their synonyms and is thus the maximum number of matches we can possibly achieve with the current method. See table for an analysis of the overlap between MeSH-Neoplasms and Wikipedia.
| MeSH Version | (1) MeSH Neoplasms | (2) Found in Wikipedia | Percent in Wikipedia |
|---|---|---|---|
| 2004 | 405 | 147 | 36.3 |
| 2008 | 636 | 227 | 35.7 |
| Search Results | Expansion Threshold | min p(Domain|Article) | |
|---|---|---|---|
| 1 | 40 | 0.5 | 0.1 |
| 2 | 40 | 0.5 | 0.4 |
| 3 | 25 | 0.8 | 0.5 |

We performed the comparison with the MeSH C04 Neoplasms subtree using three different experimental setups for domain hierarchy generation; ranging from more precision-oriented to more recall-oriented. By changing the thresholds in various steps in the algorithm as seen in Table , we achieve more expansion or more reduction. Recall oriented means using a lower search threshold (more initial results), a lower expansion threshold (more similar nodes) and a low domain-importance threshold (fewer nodes deleted because of conditional probability). Precision-oriented means that higher thresholds were set. We evaluated the created domain hierarchies with respect to the MeSH versions of 2004 and 2008. We achieve a precision of up to 48 Even though the scope of the extracted hierarchy is different from the gold standard, the focus was the same. Out of a total of 222 extracted instances in the high-precision model (Experiment 3), 135 belong to the category types of cancer. Other categories and terms that are relevant to the neoplasms domain can also be found, such as radiobiology and therapy, which, amongst others, share the instance Radiation therapy as well as Chemotherapeutic agents, Tumor suppressor gene and Carcinogens. These additional, non-MeSH finds exemplify the difference in scope between Doozer's domain hierarchy and MeSH. Whereas the MeSH C04 subtree restricts itself to listing different types of neoplasms, Doozer discovers many related concepts that are important for classification, but do not represent types of neoplasms. We take this as a strong indication that Doozer performs well in the task of producing domain hierarchies even is such a specialized domain as the neoplasms field.
References
<references/>