RDF Graph Model
Contents
RDF Graph Model
We propose a new formal model for representing any set of RDF triples as mathematical graphs.
Example
| Triple | Subject | Predicate | Object |
|---|---|---|---|
| T1 | BobDylan | isMarriedTo | SaraLownds |
| T2 | BarackObama | isMarriedTo | MichelleObama |
| T3 | isMarriedTo | rdfs:subPropertyOf | isSpouseOf |
| T4 | BobDylan | isSpouseOf | SaraLownds |
| T5 | BarackObama | isSpouseOf | MichelleObama |
For the set of RDF triples in the table above, we explain how each approach represents them in the graph.
The NLAN model

The BI model

The LDM model

More complex examples
Singleton_Property approach to representing

Empirical studies
RDF Datasets
We use four RDF datasets that are publicly available on the Web.
- BKR-SP: created by Vinh Nguyen et al. ACM. This dataset is available at Singleton_Property.
- YAGO2S-SP: also created by Vinh Nguyen et al. ACM. This dataset is also available at Singleton_Property
- DBPedia 3.9: download at DBPedia39
- Freebase: download at Freebase. For our experiment, we downloaded this dataset on March 30.
Experimental Result Files
We created multiple MapReduce jobs to compute the degree distributions of all three approaches on four RDF datasets.
Plotting Degree distributions
Here we plot the degree distributions of three approaches (LDM, NLAN, BI) on four RDF datasets.
For each dataset, we compute in-degree, out-degree, and total-degree distributions for LDM and NLAN approaches. BI approach has only total-degree distribution because it is undirected graph. We also compare the power law fit vs. exponential fit for each plot.
LDM
BKR-SP
- LDM graphs transformed from the BKR-SP dataset
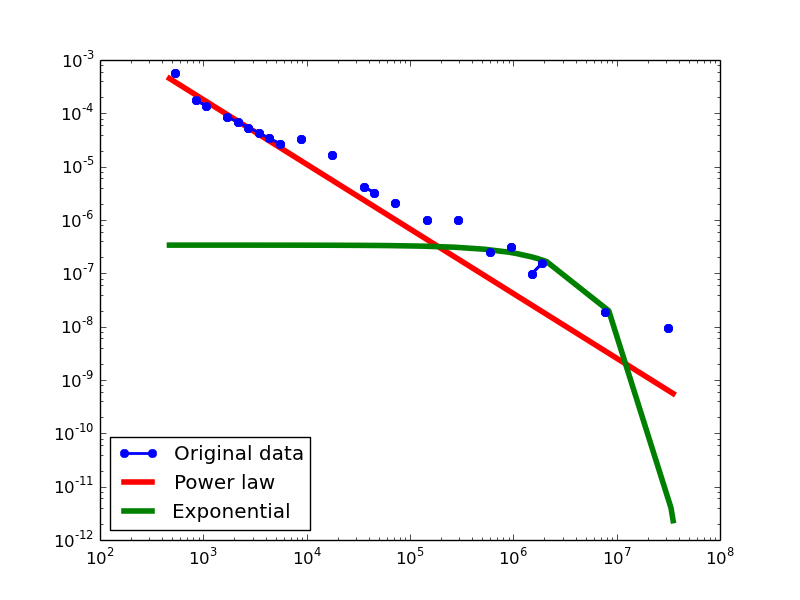
In-degree distribution.
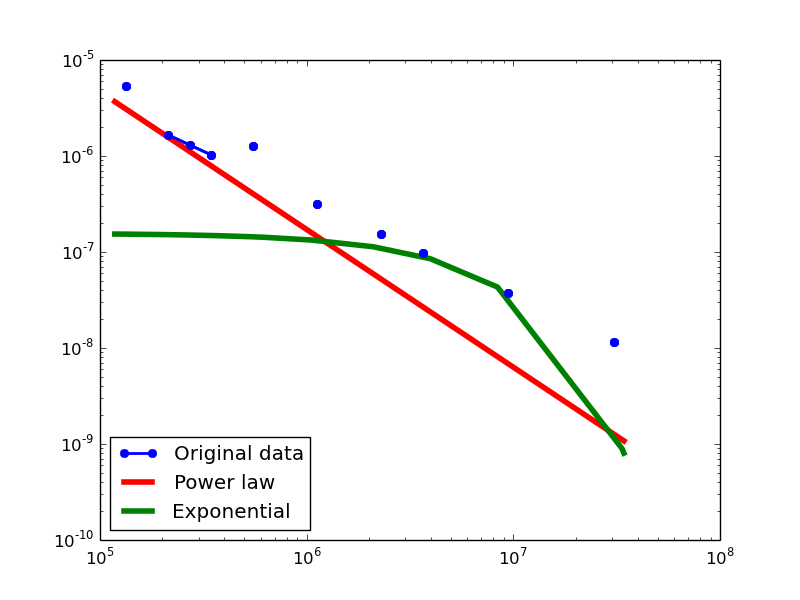
Out-degree distribution.
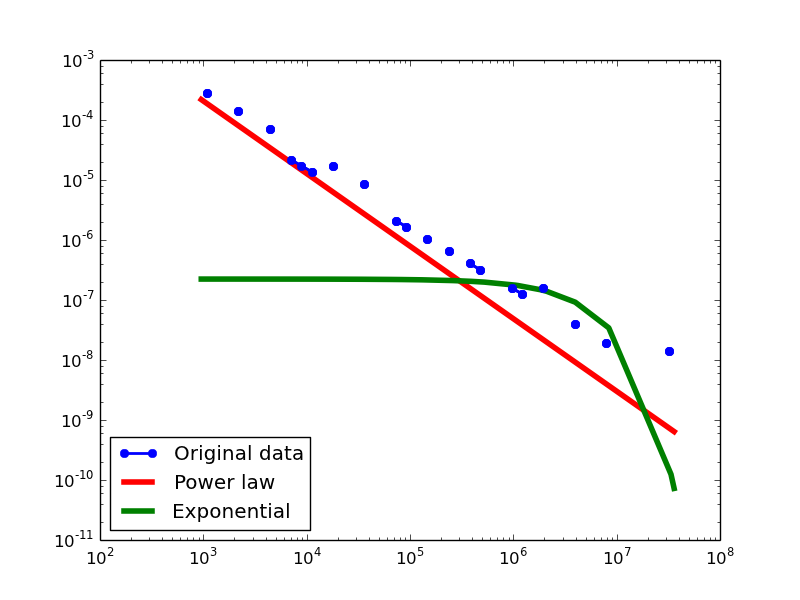
Total-degree distribution.



YAGO2S-SP
- LDM graphs transformed from the YAGO2S-SP dataset
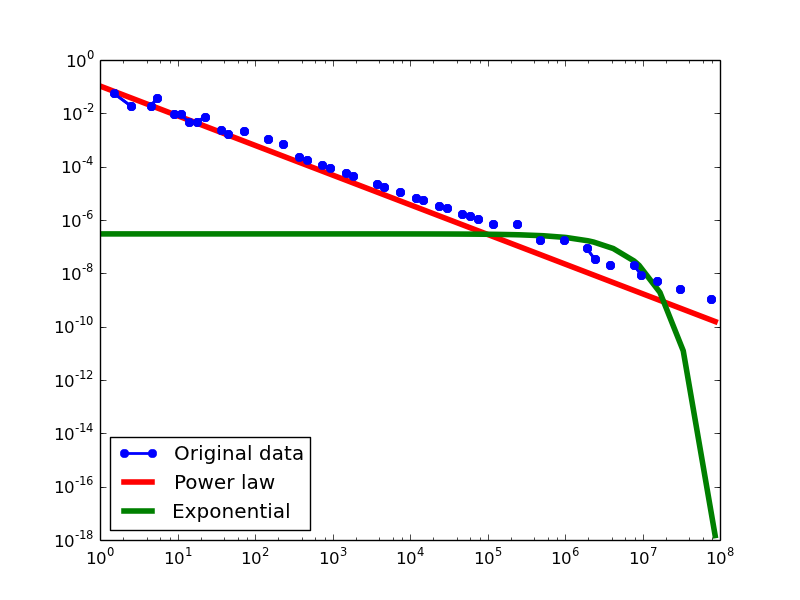
In-degree distribution.
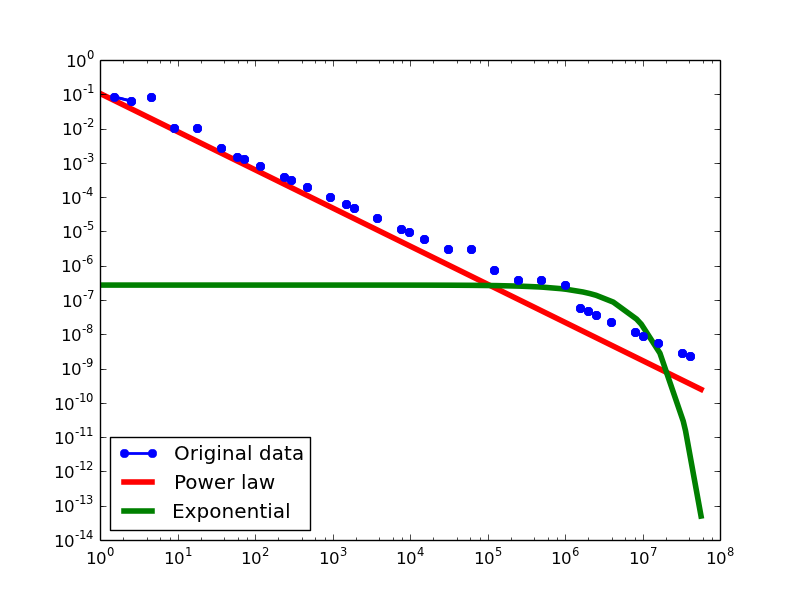
Out-degree distribution.
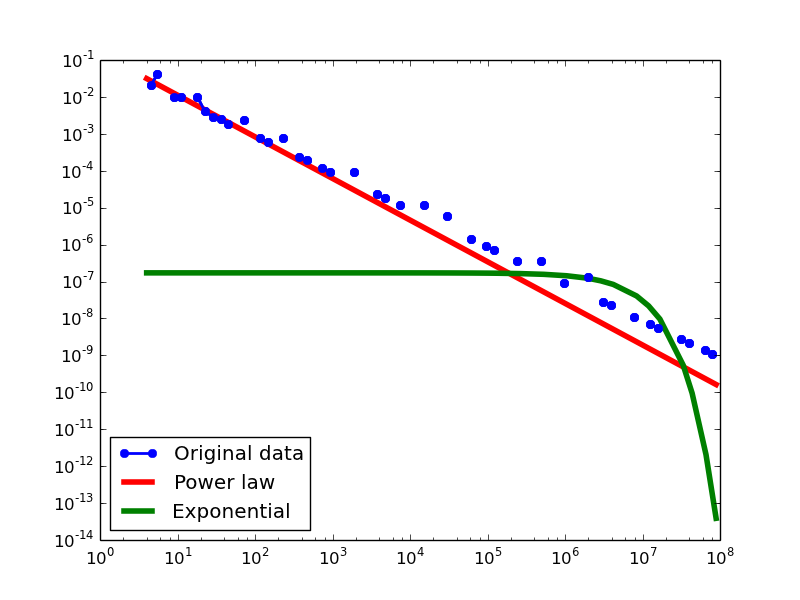
Total-degree distribution.



DBPEDIA
- LDM graphs transformed from the DBPedia dataset
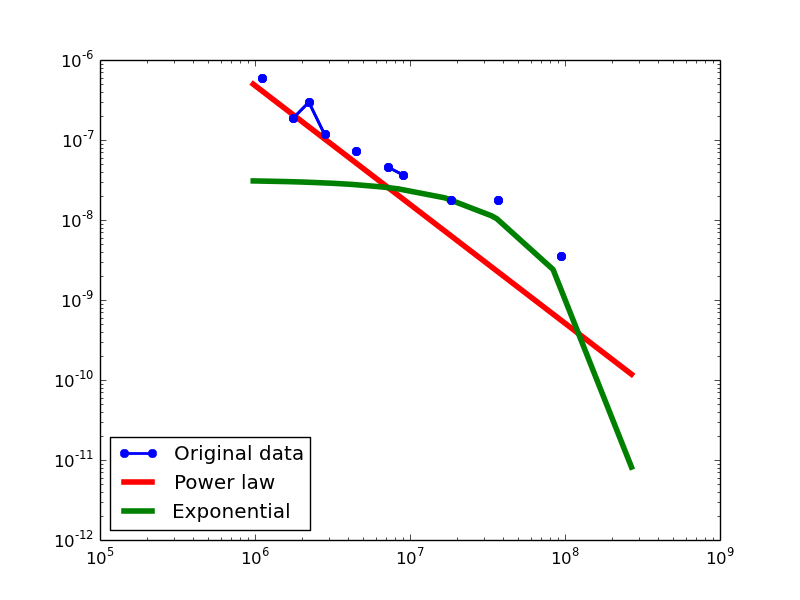
In-degree distribution.
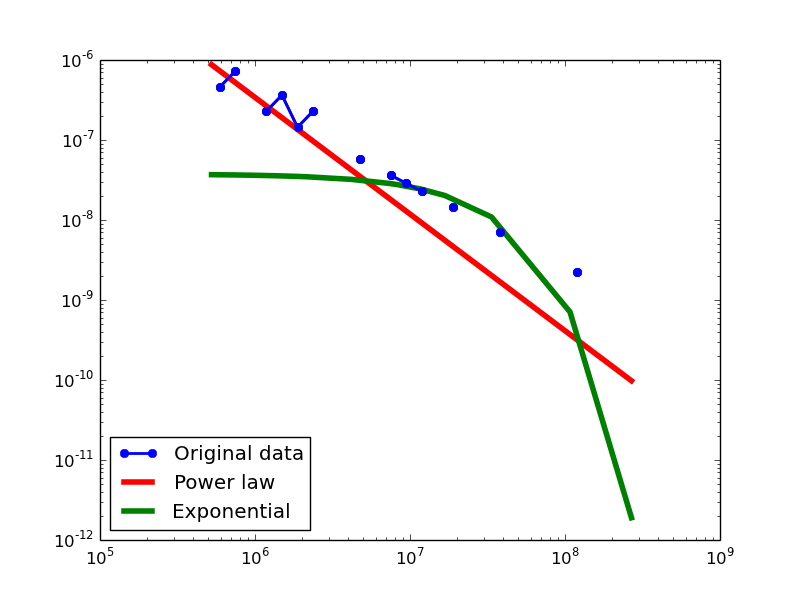
Out-degree distribution.
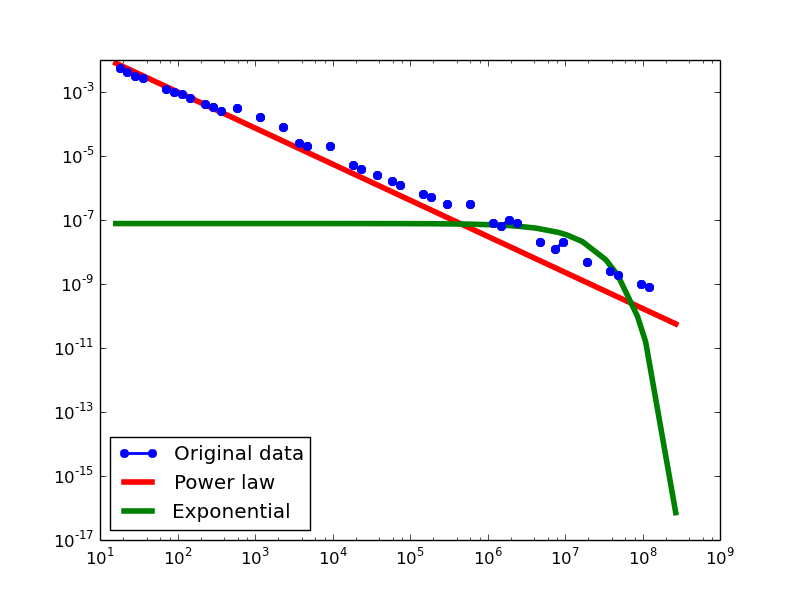
Total-degree distribution.



FREEBASE
- LDM graphs transformed from the Freebase dataset
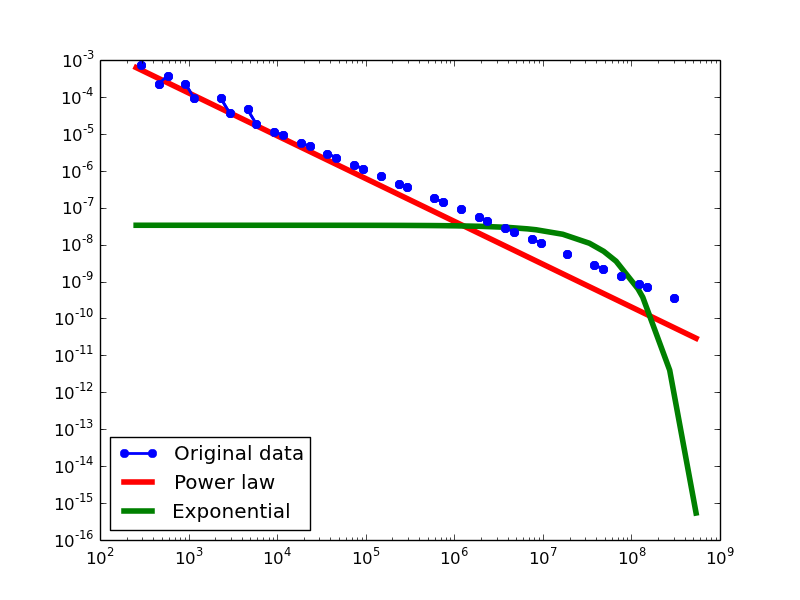
In-degree distribution.
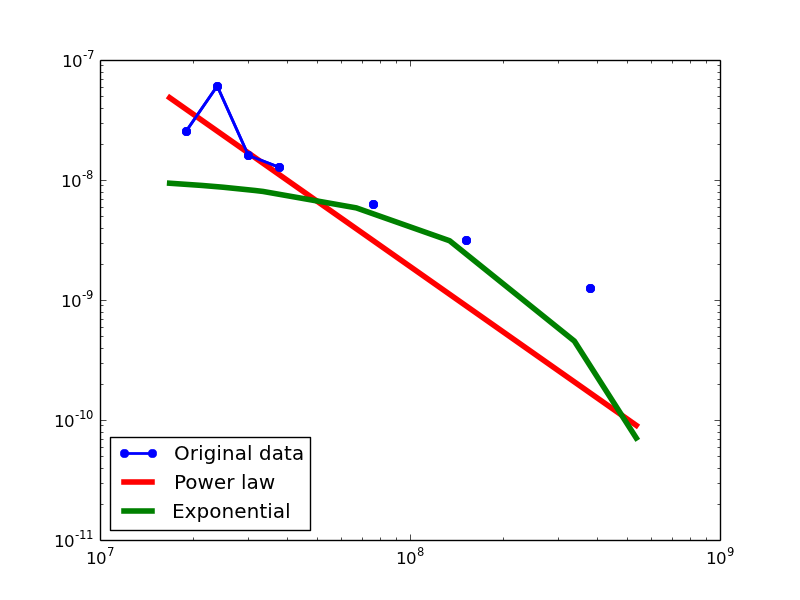
Out-degree distribution.
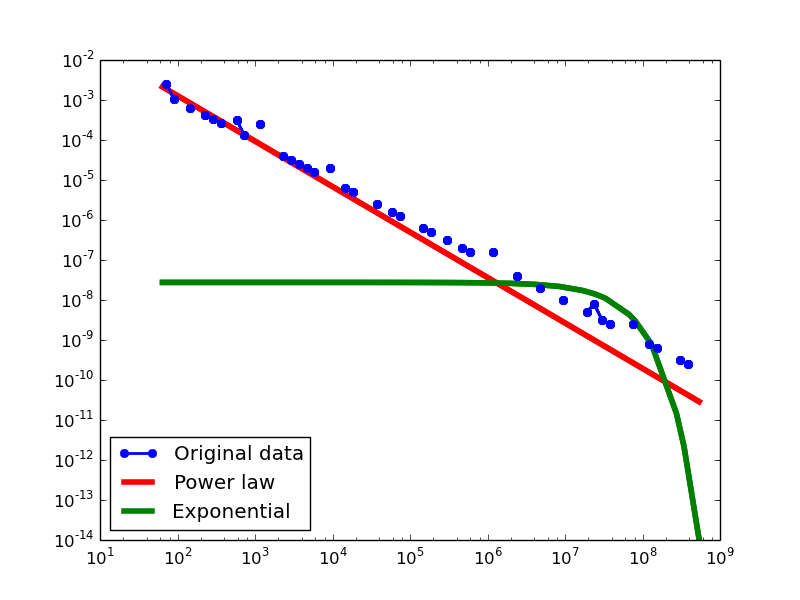
Total-degree distribution.



NLAN
This table shows the parameters of the best power law distributions for each datasets using the NLAN approach.
| Dataset | Type | alpha | xmin | Dmin | sigma | R | p |
|---|---|---|---|---|---|---|---|
| BKR-SP | in | 1.933211288 | 895825 | 0.127628625 | 0.329940015 | 2.271051161 | 0.023143881 |
| out | 1.343236826 | 3705 | 0.115026299 | 0.083247158 | 3.894424558 | 9.84E-05 | |
| total | 1.21774704 | 491 | 0.141337886 | 0.041150323 | 3.228857504 | 0.001242858 | |
| YAGO2S-SP | in | 1.123959864 | 2 | 0.13926462 | 0.017708552 | 6.236336995 | 4.48E-10 |
| out | 1.145682633 | 8 | 0.12183686 | 0.029136527 | 4.997441147 | 5.81E-07 | |
| total | 1.128566546 | 4 | 0.132747188 | 0.019165569 | 5.732859944 | 9.88E-09 | |
| DBPEDIA | in | 1.648887842 | 970956 | 0.10993169 | 0.205196353 | 1.899457176 | 0.057504392 |
| out | 1.668078604 | 715028 | 0.128189532 | 0.222692868 | 2.574136552 | 0.01004906 | |
| total | 1.566221177 | 649090 | 0.147983393 | 0.163453975 | 1.774194648 | 0.076030959 | |
| FREEBASE | in | 1.176440054 | 410 | 0.117914742 | 0.028622356 | 4.937155187 | 7.93E-07 |
| out | 1.10925354 | 1 | 0.119199458 | 0.015007128 | 6.185548611 | 6.19E-10 | |
| total | 1.148300227 | 59 | 0.123663745 | 0.0223571 | 5.311427686 | 1.09E-07 |
BKR-SP
- NLAN graphs transformed from the BKR-SP dataset
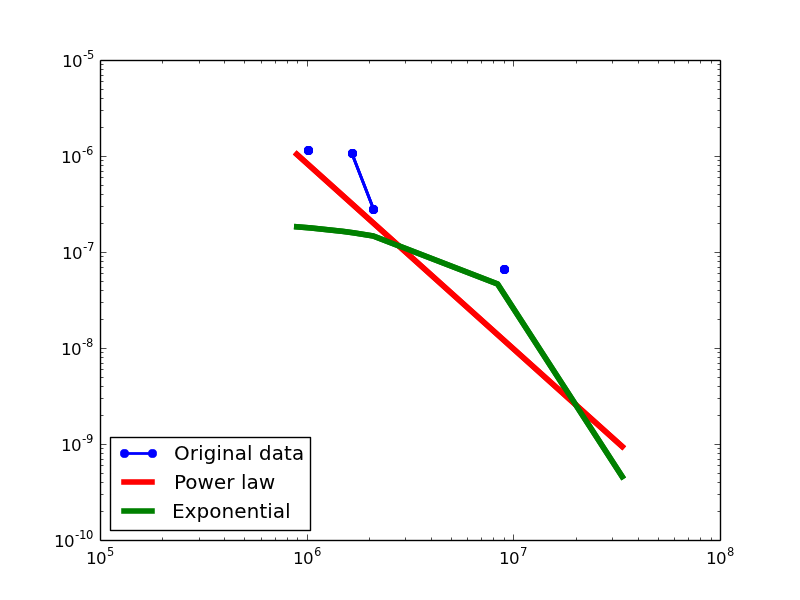
In-degree distribution.
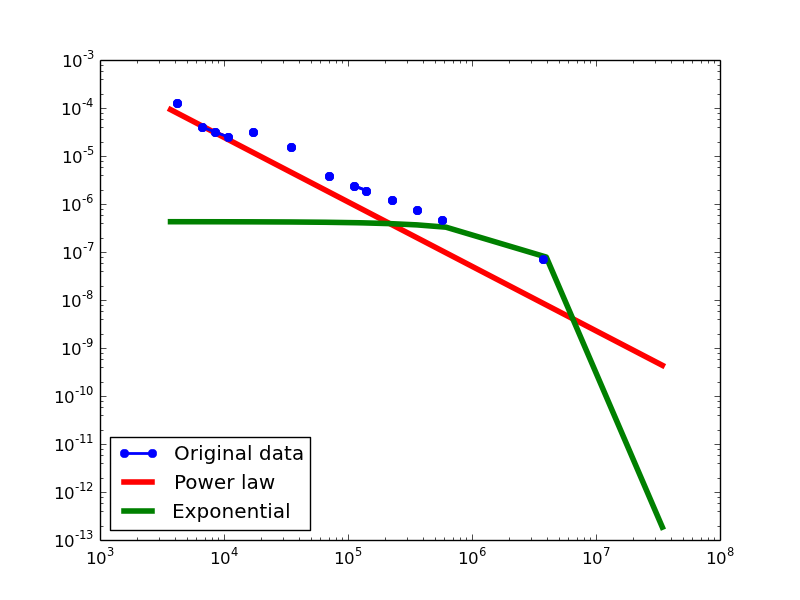
Out-degree distribution.
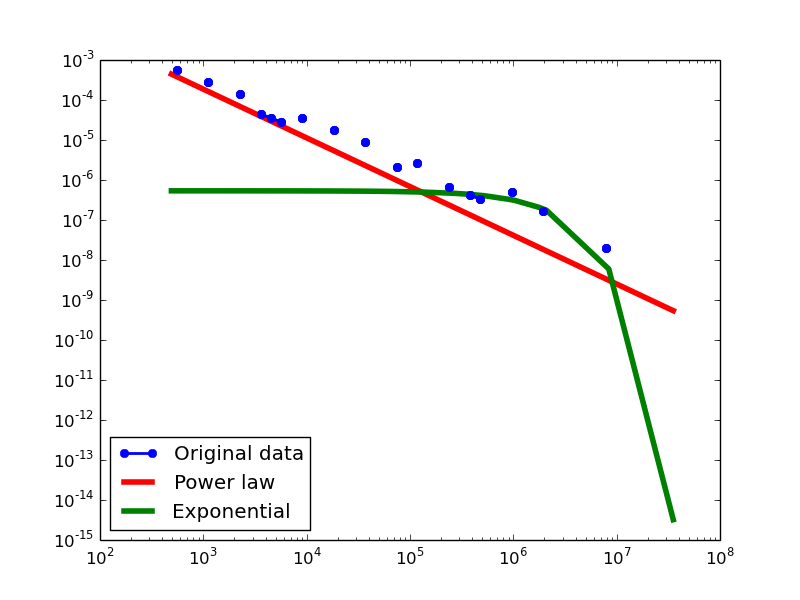
Total-degree distribution.



YAGO2S-SP
- NLAN graphs transformed from the YAGO2S-SP dataset
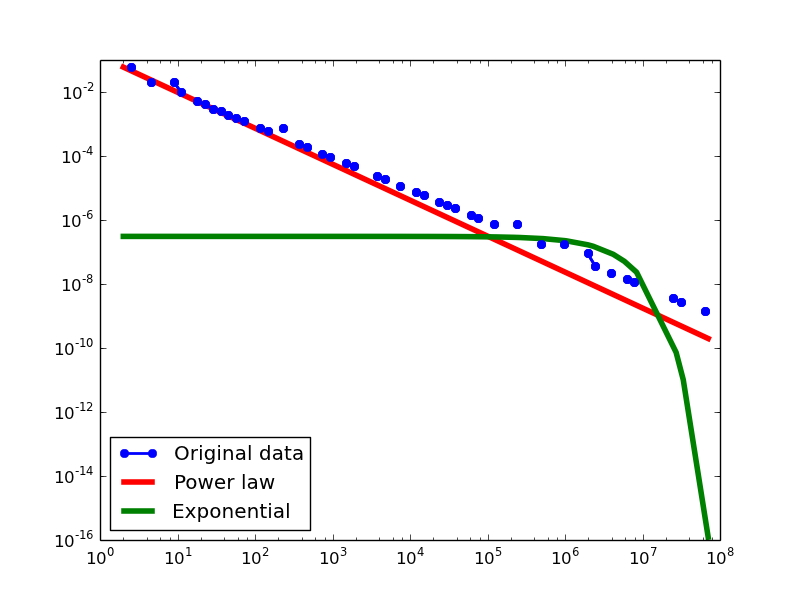
In-degree distribution.
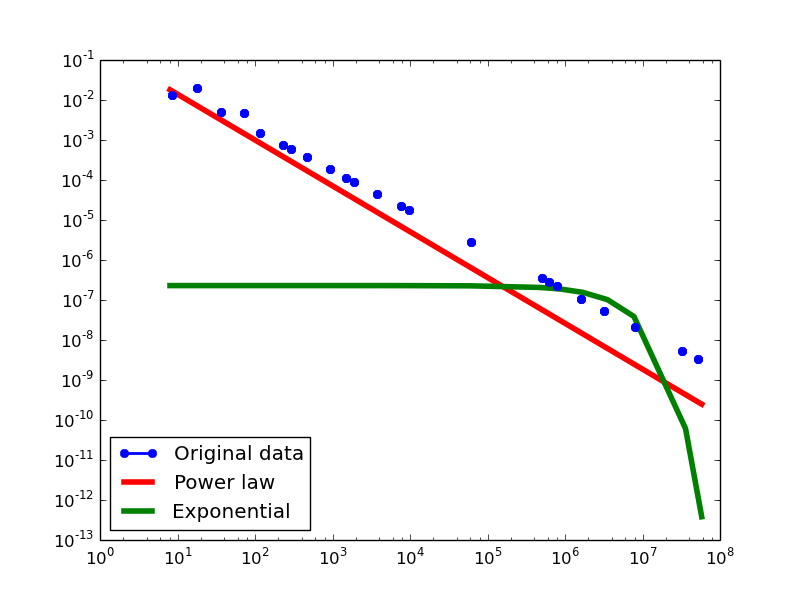
Out-degree distribution.
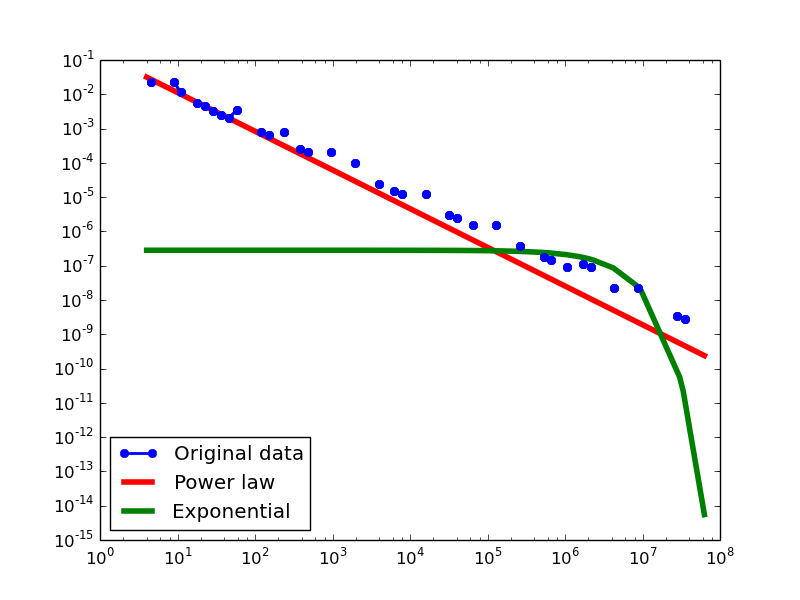
Total-degree distribution.



DBPEDIA
- NLAN graphs transformed from the DBPedia dataset
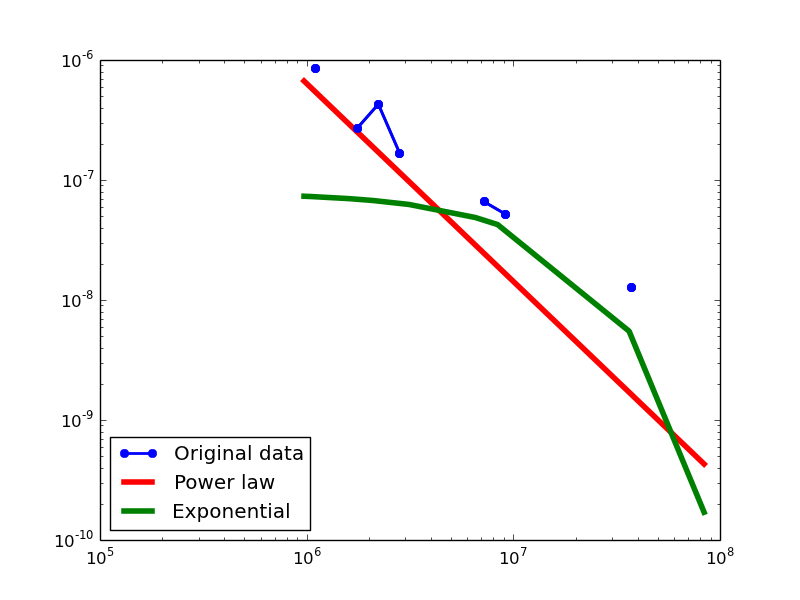
In-degree distribution.
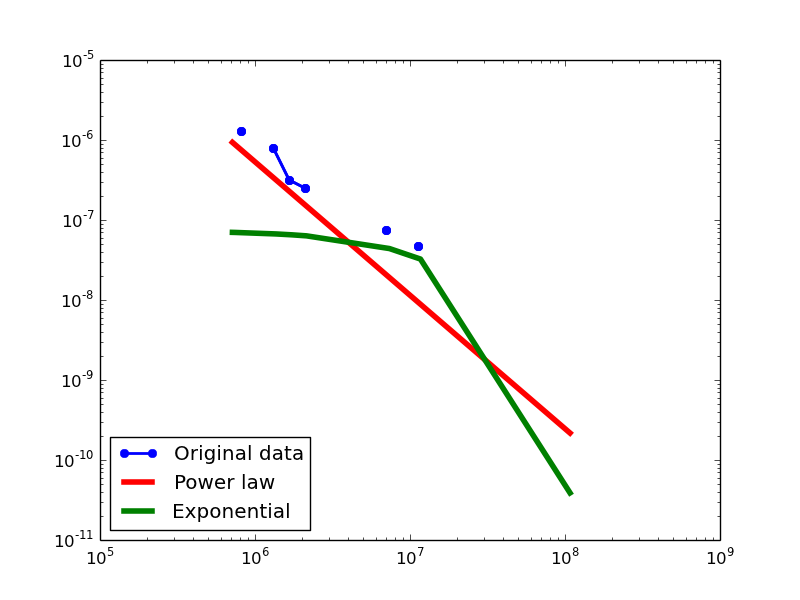
Out-degree distribution.
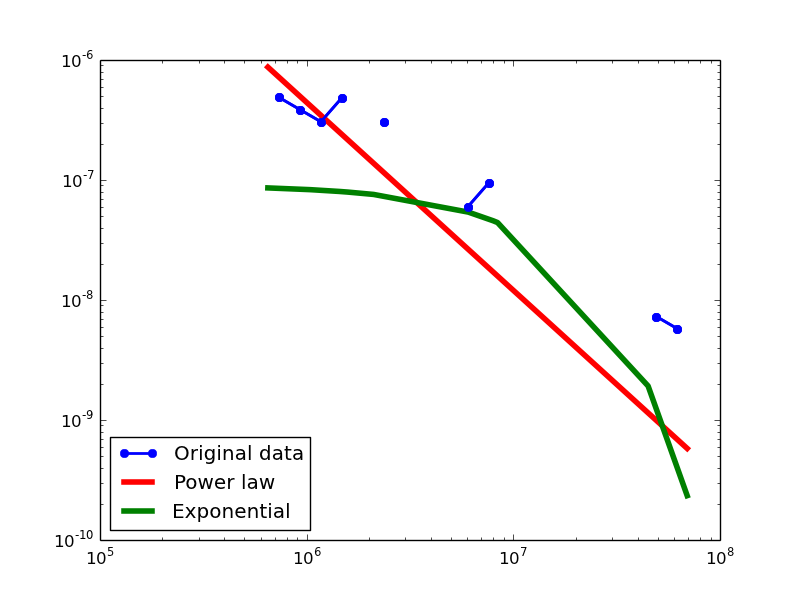
Total-degree distribution.



FREEBASE
- NLAN graphs transformed from the Freebase dataset
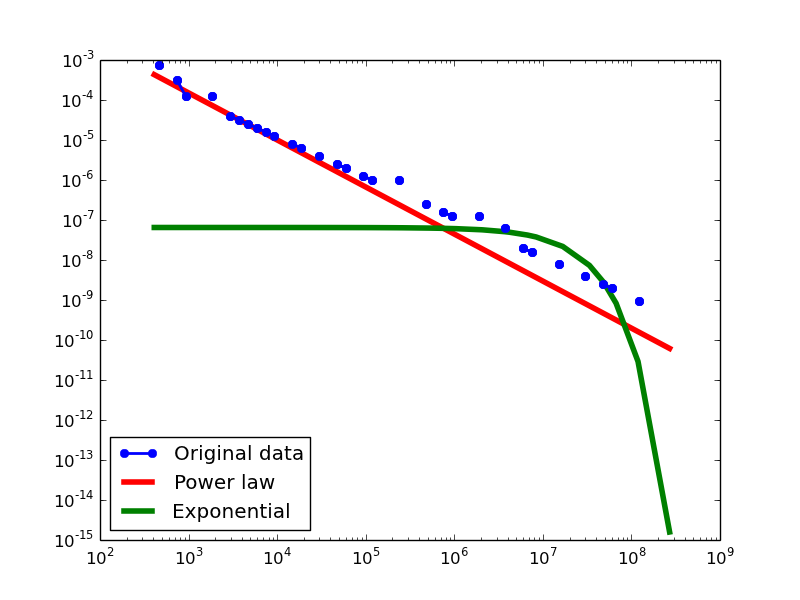
In-degree distribution.
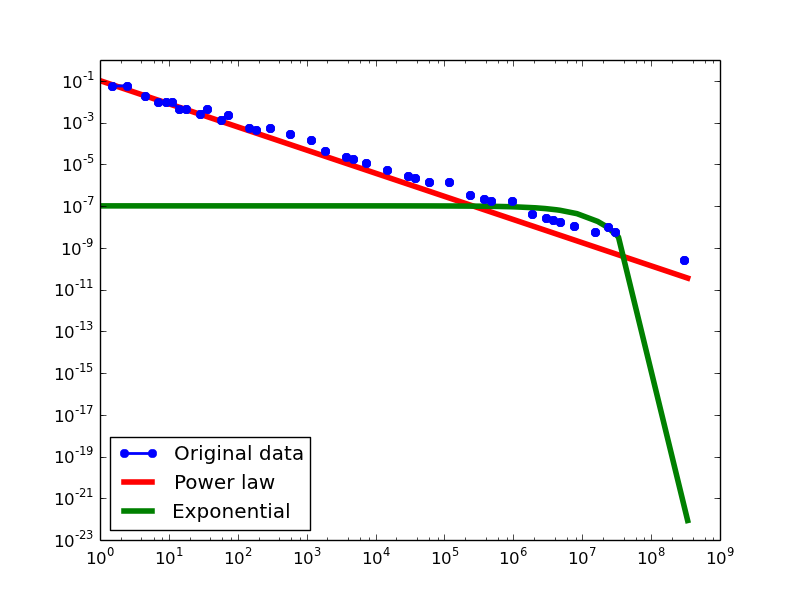
Out-degree distribution.
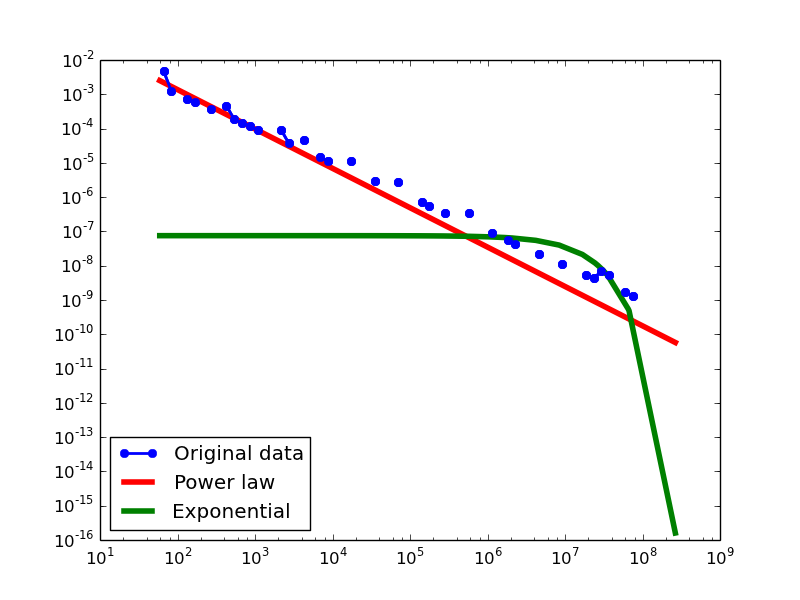
Total-degree distribution.



BI
This table shows the parameters of the best power law distributions for each datasets using the BI approach.
| Dataset | alpha | xmin | Dmin | sigma | R | p |
|---|---|---|---|---|---|---|
| BKR | 1.201698959 | 491 | 0.127904446 | 0.037454556 | 4.762452101 | 1.91E-06 |
| Yago2s | 1.129751796 | 4 | 0.124153477 | 0.018728059 | 6.136824765 | 8.42E-10 |
| DBpedia | 1.381014259 | 524288 | 0.116475129 | 0.092409531 | 2.766134059 | 0.005672521 |
| Freebase | 1.684343461 | 24352099 | 0.105289281 | 0.216408404 | 2.006340037 | 0.044819981 |
Degree Distribution
- BI graphs transformed from four datasets
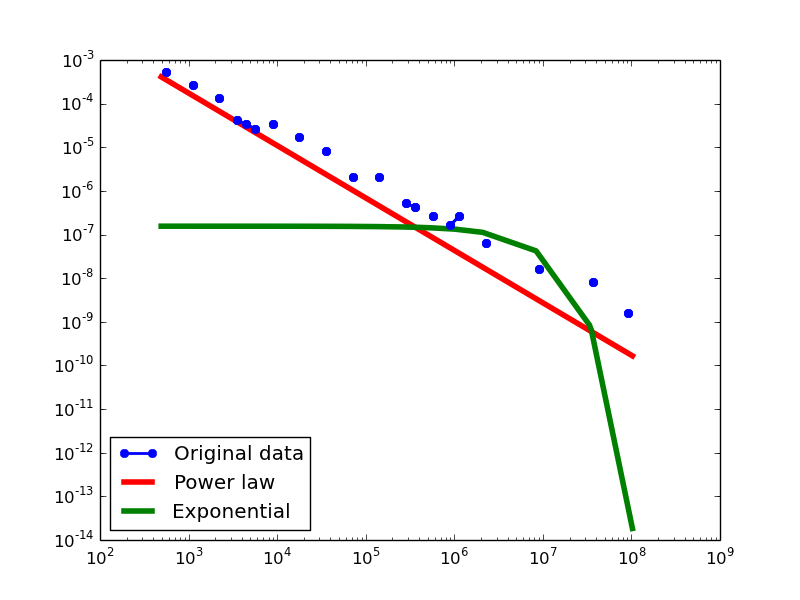
BKR total-degree distribution
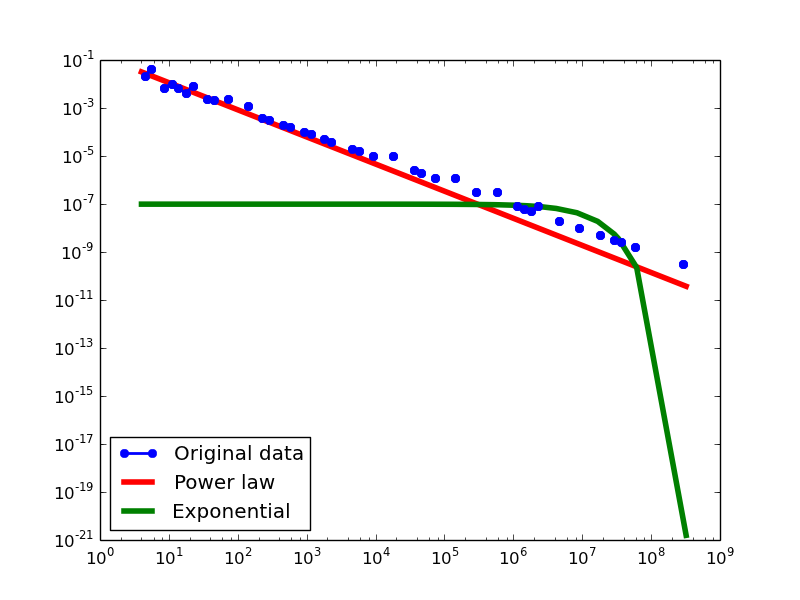
YAGO2S-SP total-degree distribution
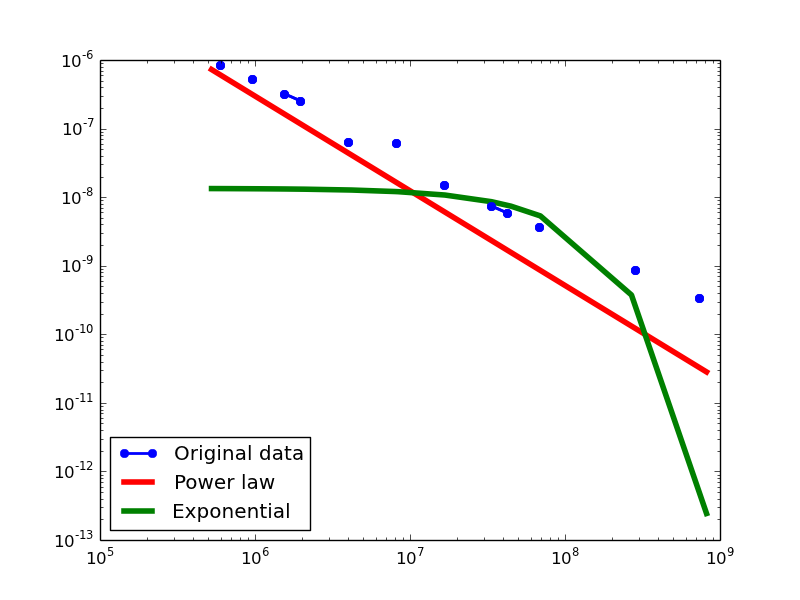
DBPEDIA total-degree distribution
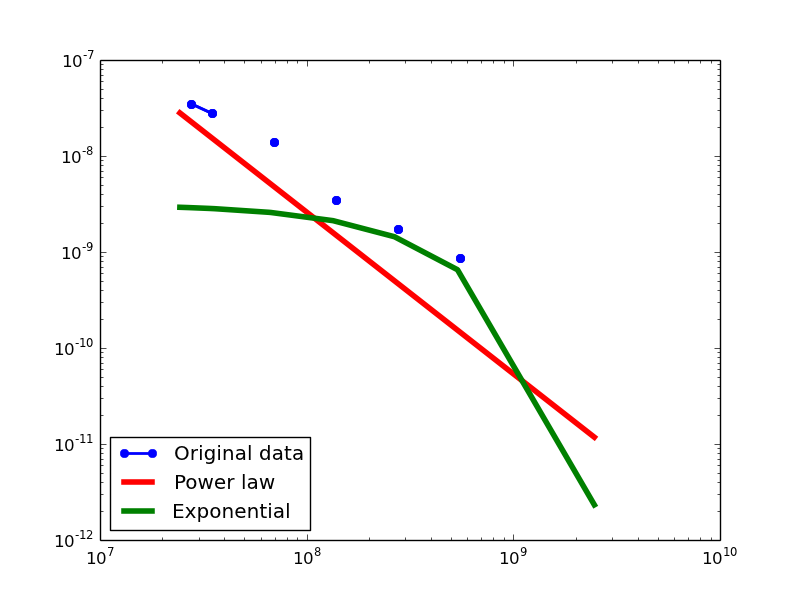
FREEBASE total-degree distribution



